
User Stories
 |
| WikiData User Stories, https://www.flickr.com/photos/psd/3731275681, CC:BY 2.0, http://creativecommons.org/licenses/by/2.0/ |
For those of you who've never heard of them, user stories come out of the agile software development world, in particular, a methodology called extreme programming. A means to improve software quality and responsiveness to changing customer requirements, user stories are "...a description...in the everyday...language of the end user or user of a system that captures what a user does or needs to do as part of his or her job function." [1]
Let's unpack that a bit:
This is important because the language that developers use ("batch-upload .png needs image size range," to use the example from Rose Pruyne's webinar) is anything but everyday language. User stories are about communication. They are a way for lay, even non-technical users of a system to communicate their ideas about a it, even if they don't speak the language of its developers. They're also a way to give broader context to developers who are often given a discrete, technical task (like "batch-upload .png needs image size range"); they ensure that a developer knows why it is they're doing what they're doing (in this example, I'm thinking that has something to do with not wanting to upload images one-by-one, and wanting to do it efficiently).
Perhaps they are even written by the "user" or "end user" of a system. While this builds on the point above, it's important to point out with the power to define the user story for a particular system or feature comes great responsibility.
As an archivist, I tend to think of myself and other archivists as "users" of a particular system, and the researchers we serve as the "end users." Even though in the case of Archivematica at the Bentley Historical Library only archivist "users" (and even then only a subset of archivists, curation archivists) will actually be interacting with the system, we have to keep in mind that any decisions we make as part of this development work are not made in a vacuum. Whatever final product is produced will inevitably affect other "users" here (such as project and reference archivists), other "users" at other institutions (that's why we're taking this show on the road!), and even current and future (Woo-hoo! Digital preservation!) "end users" of the Archival Information Packages (AIPs) we produce.
User stories, even though they don't have an exposition, rising action, climax, falling action and denouement, and even though the're not the same kind of stories you'd tell your children at bedtime (unless you really wanted to put them to sleep), are, first and foremost, stories. Moreover, they are descriptive stories that communicate who a user is and what that user does or needs to do (and, optionally, why), in very high-level terms. They are not prescriptive imperatives about how this gets done (although if you have an informed opinion, that's worth mentioning). I think this is most applicable in a web design context, although it obviously applies here as well. You may want to draw attention to your site (that's the descriptive story part, and that's OK), for example, with constantly running animations and music (prescriptive imperative, and that's not OK. That doesn't mean that you should! Trust the developers on this one--they'll draw attention to your site without annoying end users; that's their "job function."
I should also mention that user stories are supposed to be short, even short enough to fit on an index card (although we don't always follow that rule), and that they should generate conversation and as a result, get refined over time. There are also bad user stories, but I won't get into those here (see the webinar by Rose Pruyne for more information on common user story mistakes).
Importantly, it communicates the who, the what and the why (but not the how!) in simple, concise terms.
Let's unpack that a bit:
- User Stories are written in "everyday language."
This is important because the language that developers use ("batch-upload .png needs image size range," to use the example from Rose Pruyne's webinar) is anything but everyday language. User stories are about communication. They are a way for lay, even non-technical users of a system to communicate their ideas about a it, even if they don't speak the language of its developers. They're also a way to give broader context to developers who are often given a discrete, technical task (like "batch-upload .png needs image size range"); they ensure that a developer knows why it is they're doing what they're doing (in this example, I'm thinking that has something to do with not wanting to upload images one-by-one, and wanting to do it efficiently).
- User stories are written from the perspectives of "users" and "end users."
Perhaps they are even written by the "user" or "end user" of a system. While this builds on the point above, it's important to point out with the power to define the user story for a particular system or feature comes great responsibility.
As an archivist, I tend to think of myself and other archivists as "users" of a particular system, and the researchers we serve as the "end users." Even though in the case of Archivematica at the Bentley Historical Library only archivist "users" (and even then only a subset of archivists, curation archivists) will actually be interacting with the system, we have to keep in mind that any decisions we make as part of this development work are not made in a vacuum. Whatever final product is produced will inevitably affect other "users" here (such as project and reference archivists), other "users" at other institutions (that's why we're taking this show on the road!), and even current and future (Woo-hoo! Digital preservation!) "end users" of the Archival Information Packages (AIPs) we produce.
- User stories capture "what a user does or needs to do as part of his or her job function."
User stories, even though they don't have an exposition, rising action, climax, falling action and denouement, and even though the're not the same kind of stories you'd tell your children at bedtime (unless you really wanted to put them to sleep), are, first and foremost, stories. Moreover, they are descriptive stories that communicate who a user is and what that user does or needs to do (and, optionally, why), in very high-level terms. They are not prescriptive imperatives about how this gets done (although if you have an informed opinion, that's worth mentioning). I think this is most applicable in a web design context, although it obviously applies here as well. You may want to draw attention to your site (that's the descriptive story part, and that's OK), for example, with constantly running animations and music (prescriptive imperative, and that's not OK. That doesn't mean that you should! Trust the developers on this one--they'll draw attention to your site without annoying end users; that's their "job function."
I should also mention that user stories are supposed to be short, even short enough to fit on an index card (although we don't always follow that rule), and that they should generate conversation and as a result, get refined over time. There are also bad user stories, but I won't get into those here (see the webinar by Rose Pruyne for more information on common user story mistakes).
The Template
There are a couple of these out there, but here's the basic template for a user story:
 |
| User Story |
Our Archivematica > ArchivesSpace Workflow User Stories
You can take a look at all of the user stories we've created for the Archivematica feature development here. They are designed to start to take us from general to particular, from "We want to integrate Archivematica and ArchivesSpace!" to something that can actually be developed. User stories are commented on by both us here at the Bentley Historical Library and the folks at Artefactual Systems, Inc. They get refined over time, and at our weekly meetings we classify user stories by priority ("Critical", "Major", "Minor" or "Trivial") and then organize them into development sprints (e.g., aaswf_sprint1). They eventually get turned into requirements, which are recorded on the wiki, and broken up into discrete [billable] development tasks on Artefactual System, Inc.'s project management web application.
Here are a couple of representatives examples...
Tag content during appraisal (AASWF-52)
As an archivist, I would like the functionality to apply one or more tags to content (files/folders) during the appraisal process. These tags could be used for:
I would also like to be able to edit or delete tags and to search for them with facets.
- preliminary arrangement or identification of functional groups/categories of content (to be associated with AS archival objects)
- marking content for future deaccession
- identifying content to apply access/use restrictions
- other?
I would also like to be able to edit or delete tags and to search for them with facets.
This may be getting a little prescriptive at the end, but you get the picture. The comments below this example are also illuminating--we all bring our assumptions to the table that we may or may not be aware of. You'll note that this user story has been marked "Major," and will get taken care of in the first sprint. It's definitely one of our favorites!
Bulk Extractor (BE) Viewer (AASWF-35)
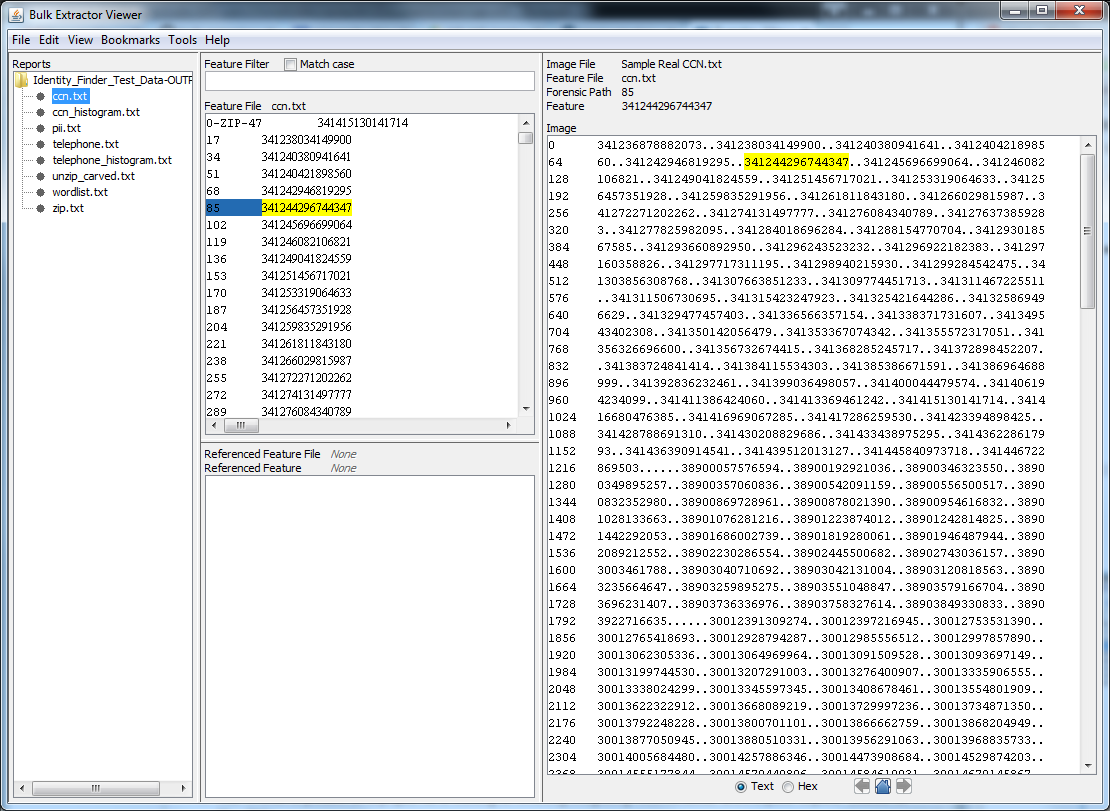
As an archivist, I'd prefer to use something like BEViewer to view Personally Identifiable Information (PII) hits in context in documents so that I don't have to open every single document separately to confirm the existence of PII.
When we discovered that our Identify Finder license expired, we took a look at a couple other tools to scan for PII. All of the tools would sometimes pick up false positives. Bulk Extractor's clear advantage was the viewer, which allows you to see PII matches in context without being forced to open individual files:
Zipping SIPs (AASWF-21)
As an archivist and user of DSpace, I need to be able to zip up 1+ files or folders that are associated with an AS Resource component, and know which ones I've zipped up, so that I can get digital content to DeepBlue in a form that it understands.
I decided to include this example because it has demonstrates that the "who" of a user story might be complex. While we, as archivists, would like this functionality, really this user story comes from the fact that we use DSpace as our digital repository. This also gets at the tension between defining user stories from the perspective of us as "users" at the Bentley Historical Library versus us as "users" in a broader, archival context.
Conclusion
Once you get started with user stories, you can't stop! Since starting our work with Artefactual Systems, Inc. we've used them to feel out another feature request in ArchivesSpace, and we've even used them internally to figure out what we're going to do with <extent> statements that we're cleaning (As it turns out, DACs is pretty loosey goosey when it comes to extents, and ArchivesSpace is the opposite. But don't worry, much, much more on that to come...).
As a reminder, you can view the rest on the ArchivesSpace JIRA project site here. See you next time!
[1] User story (this version)
No comments:
Post a Comment