
1.1 In the beginning, when Arkheion created libraries and archives, archives were a formless void.
There was no data that could be used to find materials that corresponded to a users' stated search criteria. There was no retrievable data that could be used to identify an entity. There was no data that could be used to select an entity that was appropriate to a users' needs. And, finally, there was no data that could be used in order to acquire or obtain access to the entity described.
Indeed, these were dark times.
1.2 Then Arkheion destroyed Tiamat, the dragon of primeval, archival chaos.
 |
| " |
In ancient times, libraries and archives began to organize their holdings. First by shape, then by content, then in catalogs. It wasn't long before bibliographic control as we know it today provided the philosophical basis for cataloging and our fore-librarians and fore-archivists began to define the rules for sufficiently describing information resources to enable users to find and select the most appropriate resource.
Eventually, cataloging, especially subject cataloging, and classification took root and universal schemes which cover all subjects (or, at least, the white male subjects) were proposed and developed.
1.3 Producers, Consumers and Managers lived in the fruitful, well-watered Garden of Arkheion.
And Arkheion saw that archives were good.
1.4 But darkness covered the face of the deep. Producers, Consumers and Managers lived in paradise until the storied "fall" of Managers.
 |
| The "Fall of Man[agers]" by Lucas Cranach the Elder. [2] |
To be human is to err. Human nature is fundamentally ambiguous, and it was only a matter of time before we strayed from the straight path of LCSH and AAT. We were like sheep without their shepherd. [3]
Why? Why! Maybe it was our haste. Maybe it was "human error." Maybe our fingers were just tired. Maybe we didn't want to keep track of names changes and death dates, OK!
Why? Why! Maybe it was our haste. Maybe it was "human error." Maybe our fingers were just tired. Maybe we didn't want to keep track of names changes and death dates, OK!
For better or worse, eventually the terms we were entering in our Encoded Archival Descriptions (EADs) were not the terms laid out by the controlled vocabularies we were supposed to be using. We were forever, even ontologically, estranged from Arkheion.
1.5 We lived in darkness until a savior appeared, whom two prophets (the Deutsche Nationalbibliothek and the Library of Congress) had foretold (all the way back in 2012).
The Virtual International Authority File (VIAF) is an international service designed to provide convenient access to the world's major name authority files. It's aim is to link national authority files (such as the LCSH and the Library of Congress Name Authority File or LCNAF) to a single virtual authority file. A VIAF record receives a standard data number, contains the primary "see" and "see also" records from the original records, and refers to the original authority records. These are made available online for research, data exchange and sharing. Even Wikipedia entries are being added! Alleluia!
1.6 At long last, the Virtual International Authority File (VIAF) offered us a path to reconciliation with the thesauri used by Arkheion.
And that's what this post is about, using the VIAF Application Program Interface (API) to reconcile our <controlaccess> and <origination> terms!
1.7 Amen. So be it.
So say we all. So say we all!
Using VIAF to Reconcile Our <controlaccess> and <origination> Terms
Reconciling <controlaccess> and <origination> headings, or any headings, for that matter, to the appropriate vocabularies using VIAF is a fairly simple two-step process. Somehow, we managed to make it five steps...
As a result, this is a two-part blog post!
As a result, this is a two-part blog post!
1. Initial Exploration and Humble Beginnings
Reconciling our subject and name headings to the proper authorities is something we've been considering for quite some time. Since we were spending so much time cleaning and normalizing our legacy EADs and accession records to prepare them for import to ArchivesSpace as part of our Archivematica-ArchivesSpace-DSpace Workflow Integration project, we figured that we might as well spend some time on this as well.
We'd heard about initiatives like the Remixing Archival Metadata Project (RAMP) and Social Networks and Archival Context (SNAC) (and, of course, Linked Data!), but all of those seemed pretty complicated compared to what we wanted to do, which boiled down to adding an authfilenumber attribute to <controlaccess> and <origination> sub-elements (like <persname>, <famname> and <corpname>, just to name a few) so that they would populate the "Authority ID" field in ArchivesSpace.
 |
| What we wanted. |
 |
| Why we wanted it (at least initially). |
During our initial exploration, we ran across this GitHub repository. Using Google Refine and stable, publicly available APIs, the process described in this repository automatically searches the VIAF for matches to personal and corporate names, looks for a Library of Congress source authority record in the matching VIAF cluster, and extracts the authorized heading. The end result is a dataset, exportable from Google Refine, with the corresponding authorized LCNAF heading paired with the original name heading, along with a link to the authority record on id.loc.gov.
Cool! This was exactly what we needed! Even better, it used tools we were already familiar with (like OpenRefine)! And even better than that, it was designed by a colleague at the University of Michigan, Matt Carruthers. Go Blue!
All we needed to do was pull out the terms we wanted to reconcile. For all of you code junkies out there, here's what we used for that (at least initially--this turned out to be a very iterative process). This Python script goes through our EADs and spits out three lists, one each for de-duplicated <corpame>, <persname> and <geogname> elements:
As always, feel free to improve!
Then, we added those lists to OpenRefine, created column headings (make sure you read the README!), and replayed Matt's operations using the JSON in GitHub, and got this:
 |
| OpenRefine |
Simple! It didn't find a match for every term, but it was a good start! We were feeling pretty good...
It was about this time that we realized that we had forgotten a very important step, normalizing these terms in the first place! Oops!
2. Normalizing Subjects (Better Late than Never!)
Note: For this, I've asked our intern, Walker Boyle, to describe the process he used to accomplish this.
Before we could do a proper Authority ID check, we needed to un-messify our controlled access terms. Even with our best efforts at keeping them consistent, after multiple decades there is inevitably a lot of variation, and typos are always a factor.
Normalizing them all originally seemed like something of a herculean task--we have over 100,000 individual terms throughout our EADs, so doing checks by hand would not be an option. Happily, it turns out OpenRefine has built-in functionality to do exactly this kind of task.
Given any column of entries, OpenRefine has the ability to group all similar items in that column together, allowing you to make a quick judgement as to whether the items in the group are in fact the same conceptual thing, and with one click choose which version to normalize them all into.
The first step in our process was to extract all of our control-access terms from our EADs along with their exact xml location, so that we could re-insert their normalized versions after we made the changes. This is really easy to do with Python's lxml module, and the process only takes a few seconds to run -- you can see the extraction code here. From there you just throw the output CSV into OpenRefine and start processing.
And it's super simple to use: select "Edit cells" -> "Cluster and edit") from the file menu of the column you want to edit, and choose which clustering method to use (we've found "ngram-fingerprint" with an Ngram size of 2 works best for our data, but it's worth exploring the other options). Once the clusters have been calculated, you just go down the list choosing which groups to merge into a chosen authoritative version, and which to leave alone. Once you're satisfied with your decisions, click the "Merge selected and re-cluster" button, and you're done!
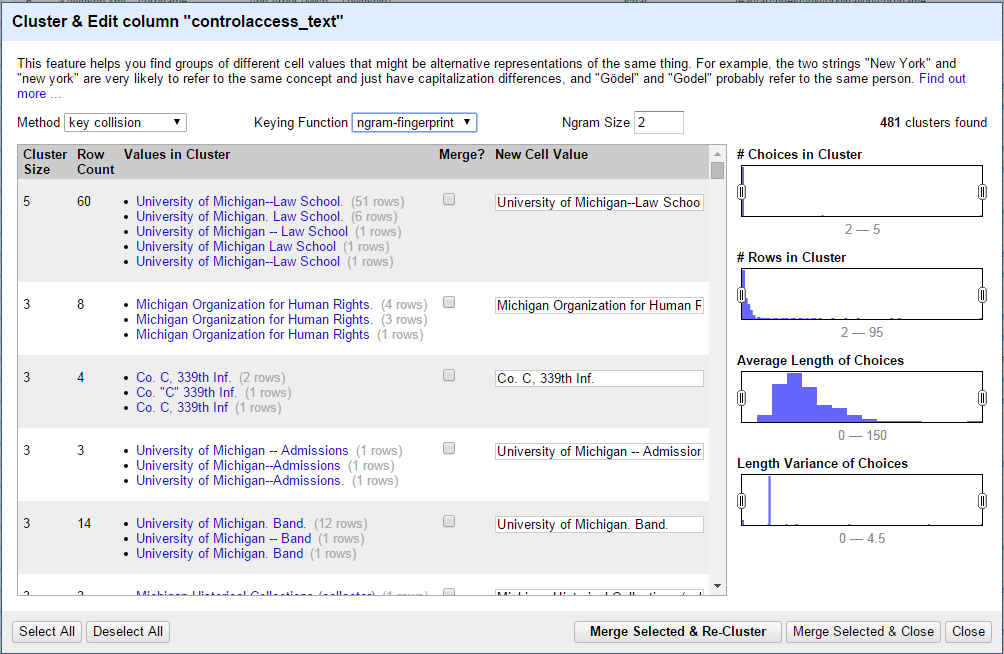 |
| Clustering in OpenRefine |
To re-insert the changed values into our EADs, we just iterated through the normalized csv data, reading the original xml path for each item and telling lxml to assign the new text to that tag (you can see our exact implementation here). One git push later, we were done. The whole process took all of an afternoon. In just a few hours, we were able to normalize the entirety of our control-access terms: some 61,000 names, corporations, genre-forms, locations, and subjects. That's pretty incredible.
3. Running the Normalized Versions through the LCNAF-Named-Entity-Reconciliation Process (Should Have Been the First Step, Oh Well)
From there, it was just a matter of exporting the CSV, creating a dictionary using the Name and LC Record Link columns, like so:
And reincorporating them back into the EAD, like so:
Zlonk! We were reconciled! Again, we were feeling pretty good...
But again we realized that we had gotten a little ahead of ourselves (or at least I did). After some sober reflection after the high of reconciliation, there were still a couple of things wrong with our approach. First, there were a lot of "matches" returned from VIAF that weren't actual matches. Some of these were funnier than others, and we tweeted out one of our favorites:
No, VIAF. Wonder, Stevie, 1950- is NOT the same as Jackson, Michael, 1958-2009. https://t.co/Wa9EzLG2in
— UM BHL Curation (@UMBHLCuration) July 9, 2015
Long story short, we needed a way to do better matching.
4. Enter FuzzyWuzzy
No, not the bear. FuzzyWuzzy is a Python library to which Walker introduced us. It allows you to string match "like a boss" (their words, not mine)! It was developed by SeatGeek, a company that "pulls in event tickets from every corner of the internet, showing them all on the same screen so [buyers] can compare them and get to [their] game/concert/show as quickly as possible."
The following quote would make Arkheion proud:
Of course, a big problem with most corners of the internet is labeling (sound familiar catalogers and linked data folks?). One of our most consistently frustrating issues is trying to figure out whether two ticket listings are for the same real-life event (that is, without enlisting the help of our army of interns).
That is, SeatGeek needs a way to disambiguate the many ways that tickets identify the same event (e.g., Cirque du Soleil Zarkana New York, Cirque du Soleil-Zarkana or Cirque du Soleil: Zarkanna) so that in turn buyers can find them, identify them, select them and obtain them.
We employed FuzzyWuzzy's "fuzzy" string matching method to check string similarity (returned as a ratio that's calculated by how many different keystrokes it would take to turn one string into another) between our headings and the headings returned by VIAF. Walker will talk more about this (and how he improved our efforts even more!) next week, but for now, I'll give you a little taste of what FuzzyWuzzy's "fuzz.ratio" function is all about.
 |
| FuzzyWuzzy's fuzz.ratio in action. |
As you can see, the higher the ratio, the fewer the number of <persname> and <corpname> elements to which we get to add an authfilenumber attribute (certainly fewer than just blindly accepting what VIAF sent back in the first place!). In the end we decided that it was better to have fewer authfilenumber attributes and fewer mistakes than the opposite! You're welcome future selves!
5. The Grand Finale
Tune in next week for the grand finale by Walker Boyle!
**UPDATE!**
Check out the exciting conclusion... Order from the chaos: Reconciling local data with LC auth records
Conclusion
This has been an exciting process, and, for what it's worth, easier than we thought it would be.While we originally started doing this to be able to get Authority IDs into ArchivesSpace, we have been getting really exciting thinking about all the cool, value-added things we may be able to do one day with EADs whose controlled access points have been normalized and improved in this way. Just off the top of my head:
- facilitating future reconciliation projects (to keep up with changes to LCNAF);
- searching "up" a hierarchical subject term like Engineering--Periodicals;
- adding other bits from VIAF (like gender values, citation numbers, publication appearances);
- interfacing with another institution's holdings;
- helping us get a sense of what we have that's truly unique;
- making linked open data available for our researchers; and
- of course, adding Wikipedia intros and pictures into our finding aids! That one hasn't been approved yet...
Can you think of more? Have you gone through this process before? Let us know!
[1] "Marduk and the Dragon" by Prof. Charles F. Horne - Sacred Books of the East *Babylonia & Assyria* 1907. Licensed under Public Domain via Wikimedia Commons - https://commons.wikimedia.org/wiki/File:Marduk_and_the_Dragon.jpg#/media/File:Marduk_and_the_Dragon.jpg
[2] "Lucas Cranach (I) - Adam and Eve-Paradise - Kunsthistorisches Museum - Detail Tree of Knowledge" by Lucas Cranach the Elder - Unknown. Licensed under Public Domain via Wikimedia Commons - https://commons.wikimedia.org/wiki/File:Lucas_Cranach_(I)_-_Adam_and_Eve-Paradise_-_Kunsthistorisches_Museum_-_Detail_Tree_of_Knowledge.jpg#/media/File:Lucas_Cranach_(I)_-_Adam_and_Eve-Paradise_-_Kunsthistorisches_Museum_-_Detail_Tree_of_Knowledge.jpg
[3] I know what you're thinking. If Arkheion is omniscient, omnipotent and omnipresent (even omnibenevolent!), how could this be so? Perhaps that's a topic for a future blog post. Also, Arkheion is not real; this whole story is made up.
No comments:
Post a Comment