With apologies to
Walter Benjamin, I would like to reflect on some of the challenges and strategies associated with the appraisal of digital archives that we've faced here at the Bentley Historical Library. The following discussion will highlight current digital archives appraisal techniques employed by the Bentley, many of which we are hoping to integrate into the forthcoming Archivematica
Appraisal and Arrangement tab.
Foundations and Principles
In working with digital archives, the Bentley seeks to apply the same archival principles that inform our handling of physical collections, with added steps to ensure the authenticity, integrity, and security of content.
By and large, appraisal tends to be an iterative process as we seek to understand the intellectual content and scope of materials to determine if they should be retained as part of our permanent collections. If we're really lucky, curation staff and/or field archivists might be able to review content (or a sample thereof) prior to its acquisition and accession, a process that helps us pinpoint the materials we are interested in and avoid the transfer of content that we have identified as out of scope or superfluous.
This pre-accession appraisal may not be possible for various reasons (technical issues, geographic distance, scheduling conflicts, etc.), but in the vast majority of cases, we have some level of understanding about the nature of digital content and its relationship to our collecting policy by the time it's received, from a high-level overview or item-level description in a spreadsheet.
Whatever the case, appraisal is a crucial part of our ingest workflow, as it helps us to:
- Establish basic intellectual control of the content, directory structure, and/or original storage environment to facilitate the arrangement and description of content.
- Identify content that should be included in our permanent collections as well as superfluous or out-of-scope materials that will be separated (deaccessioned).
- Determine potential preservation issues posed by unique file formats, content dependencies, or other hardware/software issues.
- Address copyright or other intellectual property issues by applying appropriate access/use restrictions.
- Discover and verify the presence of sensitive personally identifiable information such as Social Security and credit card numbers.
As we strive to employ More Product, Less Process (MPLP) strategies to the greatest extent possible, it is important to employ tools and strategies that will avoid inefficiencies and ensure that appraisal occurs at an appropriate level of granularity. I should also note that we take a nimble and common-sense approach to appraisal: not all procedures will be required for all accessions and in cases where donors provide detailed descriptive information for fairly homogeneous content, appraisal may be fairly minimal.
Characterizing Content
One of the first steps we take with a new digital accession is to get a high-level understanding of the volume, diversity, and nature of files. We currently glean much of this information from
TreeSize Professional, a proprietary hard disk space manager from JAM Software (similar open-source applications include
WinDirStat and
KDirStat.)
Directory Structure
The
tree command line utility, available in both
Windows and
Linux/OS X shells, provides a simple graphical representation of the directory structure in an accession.
For very large or complex folder hierarchies, it may be difficult to keep track of the parent/child relationships within the tree output. In these cases, it may be easier to review the output of dir or ls (in the Windows CMD.EXE shell, dir /S /B /A:D [folder] will provide a recursive listing of all directories within a folder) or to review the directory structure in a file manager or other application.
Relative Size of Directories
Knowing where the largest number or volume of files are located in a directory structure can be helpful in identifying areas of the accession that might require additional work or where more extensive content review will be required. TreeSize Professional produces various visualizations of the relative size of directories in pie charts, bar graphs, and tree maps and permits archivists to toggle between views of the number of files, size, and allocated space on disk:
Clicking on an element of a graph or chart will permit you to view a representation of the next level, a process that may be repeated until you drill down to the files themselves.
Age of Files
Determining the 'age' of files requires analysis of filesystem
MAC times (Modification, Access, and Creation times), which can be a little dicey, especially if content has been migrated from one type of file system to another (the specifics of which I won't try to get into...). TreeSize permits archivists to create custom intervals to define the age of files and will create visualizations based on any of the MAC times (we generally use last modified, as it often coincides with creation dates and indicates when the content was last actively used). Clicking on any of the segments in the graph will produce a list of all files associated with that interval:
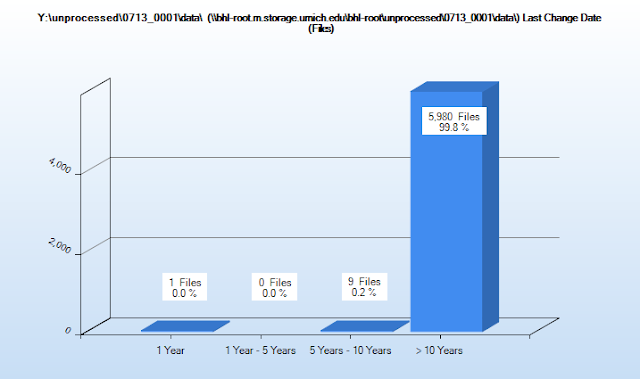
While this information may not be useful if the donor has accidentally altered the timestamps during the transfer process, knowing that there are especially old files in an accession can help guide our review of content and prepare us for any additional preservation steps that might be required. For instance, knowing that a collection includes word processing files in a proprietary file format from the 1990s might lead us to explore additional file format migration pathways if the content is of sufficient value.
File Format Information
We've also found it helpful to see information about the breakdown of file formats in an accession to better understand the range of materials and assist with preservation planning, in the event that high-value content is in a unique file format or is part of a complex digital object that requires additional preservation actions. TreeSize presents a table of file format information (also available for download as a delimited spreadsheet or Excel file) that arranges content into file format types defined by the archivist ('video files', 'image files', etc.) and which includes the number and relative size of files associated with a given format. A bar chart also provides a visual representation of the file format distribution; right-clicking on any format will give an option to see a complete listing (with full file paths) of associated content:
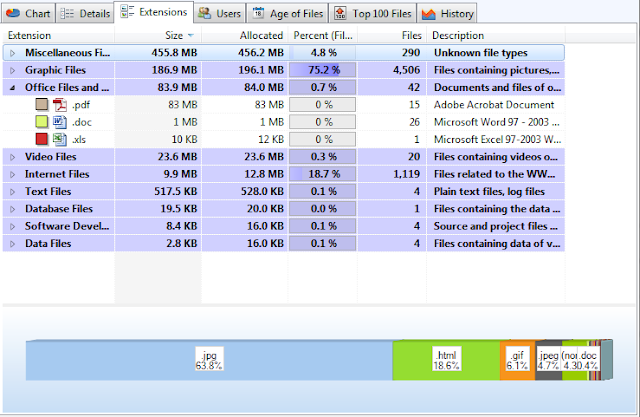
It's important to note that TreeSize Professional only reviews file extensions in producing these reports (as we're only looking for a general characterization of an accession, we can live with this potential ambiguity). The 'Miscellaneous' or 'Unknown file types' in the first line of the above screen shot thus include files with extensions that have not been identified in the TreeSize user interface or operating system default applications for files. If more accurate information is needed, running a file format identification utility such as
DROID,
fido, or
Siegfried (all of which consult the PRONOM file format registry). We actually have an
additional step in our workflow that cycles through all files identified as having an 'extension' mismatch and uses the PRONOM registry and the
TrID file identification tool to suggest more accurate extensions.
Duplicate Content
TreeSize Professional also has a default search that will identify duplicate content within a search location based upon MD5 checksum collisions, with results available in a table (and also via spreadsheet export).
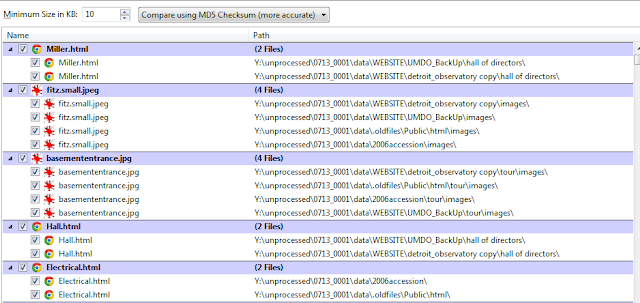
I've long felt that managing duplicate content in a digital accession can be tricky business due to the amount of work required to make informed decisions. From an MPLP approach, it doesn't make sense to weed out individual duplicate files, especially when it can be difficult (if not impossible) to determine which version of a file may be the record version. In addition, we often find that 'duplicate' files may actually exist in more than one location for good reason. For instance, a report may have been created and stored in one part of a directory structure and then stored again alongside materials that were collected for an important executive committee meeting. We've therefore resigned ourselves to having some level of redundancy in collections and primarily use duplicate detection to identify entire folders or directory trees that are backups and suitable candidates for separation or deaccesioning.
Reviewing Content
While the steps described above help identify potential issues and information based on broad characterizations, we also manually review files to verify the potential presence of personally identifiable information and better understand the intellectual content of an accession. In keeping with our MPLP approach, we only seek to review a representative sample of content (much as we do with physical items) and browse/skim documents to understand the nature and basic function of records. In-depth review is reserved for particularly thorny arrangement/description challenges or high-value collections that require a more granular approach.
Identification of Personally Identifiable Information
We conduct a scan and review of personally identifiable information (such as Social Security numbers and credit card numbers) as a discrete workflow step, but it still constitutes an important aspect of appraisal. At this point, we are using
bulk_extractor (and primarily the 'accounts' scanner) with the following command (the '-x' options prevent additional scanners from running):
bulk_extractor.exe -o [output\directory] -x aes -x base64 -x elf -x email -x exif -x gps -x gzip -x hiberfile -x httplogs -x json -x kml -x net -x rar -x sqlite -x vcard -x windirs -x winlnk -x winpe -x winprefetch -R [target\directory]
We then launch Bulk Extractor Viewer, which allows us to review the potential sensitive information in context to verify if it represents a potential issue.
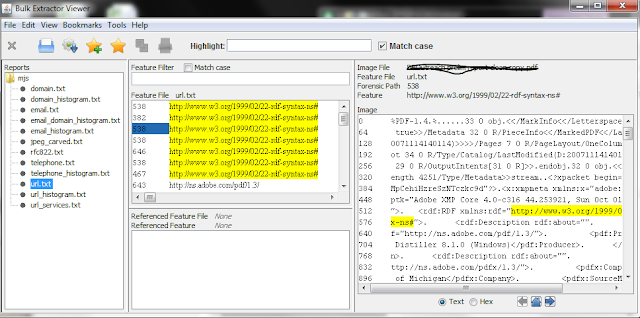
Based upon this review, we may delete nonessential content or use BEViewer's 'bookmark' feature to track content that will need to be embargoed with an appropriate access restriction.
Quick View Plus
The proprietary Windows application
Quick View Plus (QVP) is our go-to tool when we need to review content. In addition to being able to view more than 300 different file formats, QVP will not change the 'last accessed' time stored in the file system metadata.
The QVP interface is divided into three main parts in addition to the navigation menu and ribbon at the top of the application window. The right portion of the interface holds the Viewing Environment while the left-hand side is divided between the Folder Pane (which can also be used to review the directory structure) on the top and the File Pane on the bottom.
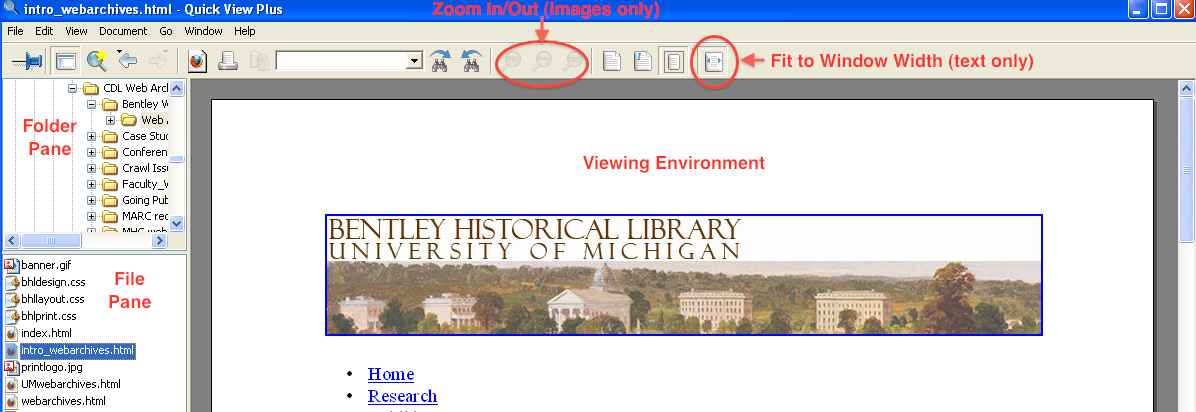
After QVP opens, the right and left arrows may be used to expand/collapse subfolders and navigate to the appropriate location in the Folder Pane. Once a folder has been selected, a list of its contents (both subfolders and files) will be displayed in the File Pane; after a file is selected, it will appear in the Viewing Environment. While we've noticed some issues with the display of PDF files, QVP meets the vast majority of our content review needs. Moving to the browser-based (and open source) environment of Archivematica, it will be interesting to see how well we are able to view/render content using standard browser plugins. We'll keep you posted...
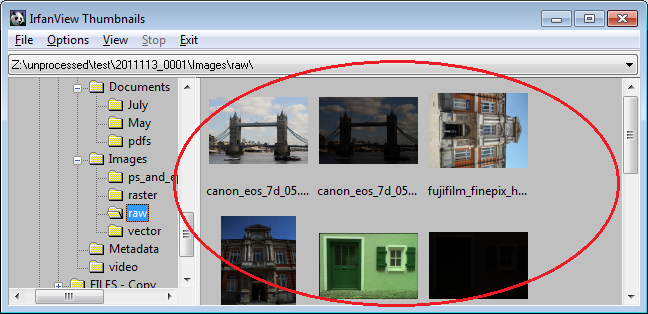
Image Viewers: IrfanView and Inkscape
While QVP can handle pretty much every raster image we throw at it, the 'thumbnail' interface of
IrfanView is pretty handy when we need to browse through folders that primarily contain images:
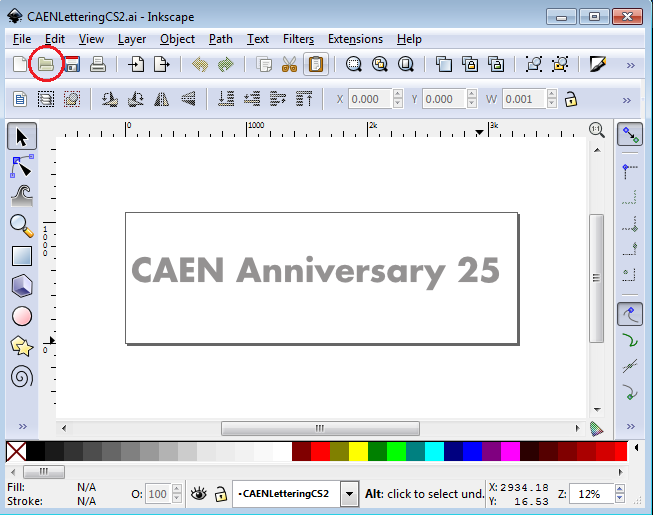
QVP is not able to render vector graphic files and so we employ
Inkscape when we encounter such content.
It's open source and freely available (and can also be used via the command line for file format conversion)--if you haven't checked it out, have at it!
Sound Recordings and Moving Images
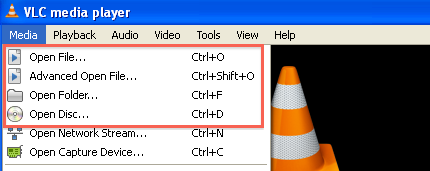
When it comes to reviewing sound recordings and moving images,
VLC Media Player is our preferred app. An open-source project that supports a ton of audio and video codecs, VLC permits you to load an entire directory of audio/video as a playlist that you can then advance through.
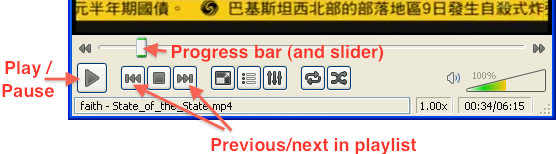
Play controls are located at the bottom of the Media Player window; in addition to Play, Pause, and Stop buttons, the archivist may fast forward or reverse progress by adjusting the slider on the progress bar.
So...What's in Your Wallet?
At the end of the day, appraisal is about making informed choices concerning what we will include in our final collections and how that material will be arranged, described, and made accessible. While some aspects can be automated (and there's clearly a lot more potential work that enterprising archivists/techies could explore via natural language processing, topic modeling, facial recognition software, automated transcription), there is also a need for human intelligence to decide what to deaccession, what to keep, and how it will be described. Or at least that's our take--please feel free to share what tools and strategies you employ at your institution!
















 Based upon this review, we may delete nonessential content or use BEViewer's 'bookmark' feature to track content that will need to be embargoed with an appropriate access restriction.
Based upon this review, we may delete nonessential content or use BEViewer's 'bookmark' feature to track content that will need to be embargoed with an appropriate access restriction.