
Hope you enjoy it!
Format Policy Registry (FPR)
Located in the "Preservation planning" tab, the Archivematica Format Policy Registry (FPR) is a database which allows users to define format policies for handling file formats.Formats

In the FPR, "a 'format' is a record representing one or more related format versions, which are records representing a specific file format" (Format Policy Registry [FPR] documentation). As you can see from the example above, the "Graphics Interchange Format" format is made up of 3 specific versions, "1987a," "1989a," and "Generic gif."
Formats themselves are described this way:
- Description: Text describing the format, like a name.
- Version: The version number for that specific format.
- PRONOM ID: The specific format version’s unique identifier in PRONOM, the UK National Archives’s format registry.
- Access format? and Preservation format?: This is where you indicate that whether something is suitable for access or preservation purposes, or both or neither.
Format Policies
In Archivematica, format policies act on formats. Format policies are made up of:- Tools: Tools are things like 7Zip, ImageMagick's convert command, ffmpeg, FFprobe, FITS, Ghostscript, Tesseract, MediaInfo, etc., which come packaged with Archivematica.
- Commands: These are actions that you can take with a tool, e.g., "Transcoding to jpg with convert" or "Transcoding to mp3 with ffmpeg." Commands can be used in one of the following ways:
- Identification: The process of trying to identify and report the specific file format and version of a digital file.
- Characterization: The process of collecting information (especially technical information) about a digital file.
- Normalization: Migrating/transcoding a digital file from an original format to a new file format (for access or preservation purposes).
- Extraction: The process of extracting digital files from a package format such as ZIP files or disk images.
- Transcription: The process of performing Optical Character Recognition (OCR) on images of textual material.
- Verification: The process of validating a digital file produced by another command. Right now these are pretty simple, e.g., check that it isn't 0 bytes.
- Rules: This is where you put it all together and apply a specific command to a specific format, saying something like: "Use the command 'transcoding to tif with convert' on the 'Windows Bitmap' format for 'Preservation' purposes." When browsing the FPR you can actually see how well these policies are working out. In our case, this particular policy has been successful for 2 out of 2 digital files we attempted it on.
The first time a new Archivematica installation is set up, it will register the Archivematica install with the FPR server [1], and pull down the current set of format policies. FPR rules can be updated at any time from within the Preservation Planning tab in Archivematica (and these changes will persist through future upgrades). You also have the option of refreshing your version with the centralized Archivematica FPR server version, if you so choose.
Customizing Archivematica's Format Migration Strategies
What follows is our initial foray into customizing Archivematica's format migration strategies. For a more detailed look at this as well as customizing other aspects of the FPR, you should definitely check out the documentation.What We Do Now
For some context, we've been normalizing files for quite some time. Because we must contend with thousands of potential file formats, a number of years ago we adopted a three-tier approach to facilitate the preservation and conversion of digital content:- Tier 1: Materials produced in sustainable formats will be maintained in their original version.
- Tier 2: Common “at-risk” formats will be converted to preservation-quality file types to retain important features and functionalities.
- Tier 3: All other content will receive basic bit-level preservation.
These, by the way, are being incorporated into a more comprehensive Digital Preservation Policy which we hope to share with others in the near future...
Comparing Our Format Migration Strategies to Archivematica's
We decided to make some customizations to Archivematica's FPR because some of our existing policies didn't quite match up with Archivematica's. We discovered this by doing an initial comparison of the FPR with our existing Format Conversion Strategies for Long-Term Preservation.For a detailed list of all of our findings, please see this spreadsheet. Basically, however, here's how things broke down for the 62 formats in Tiers 1 and 2 that I examined in depth:
- Formats we recognized as preservation formats, and are an Archivematica preservation format.
Examples: Microsoft Office Open XML formats, OpenDocument formats, TXT, CSV and XML files, WAV files, PNG and JPEG2000 files, etc.
- Formats we recognized as preservation formats, but aren't an Archivematica preservation format. These have a normalization pathway.
Examples: AIFF and MP3 files, and also lots of video: AVI, MOV, MP4.
- Formats we recognized as preservation formats, but aren't an Archivematica preservation format. These have no normalization pathway.
These were the most varied, including files belonging to the PDF, Word Processing, Text, Audio, Video, Image, Email and Database groups. Examples: PDF/A files, RTF and TSV files, FLAC and OGG files, TIFF files and SIARD files.
- Formats we didn't recognize as preservation formats, but are an Archivematica preservation format.
These were mostly things like older Microsoft Office formats, mostly. Examples: DOC, PPT and XLS files.
These, by the way, are our most common Tier 2 formats based on an analysis of our already processed digital archives I did for Code4Lib Midwest this year:
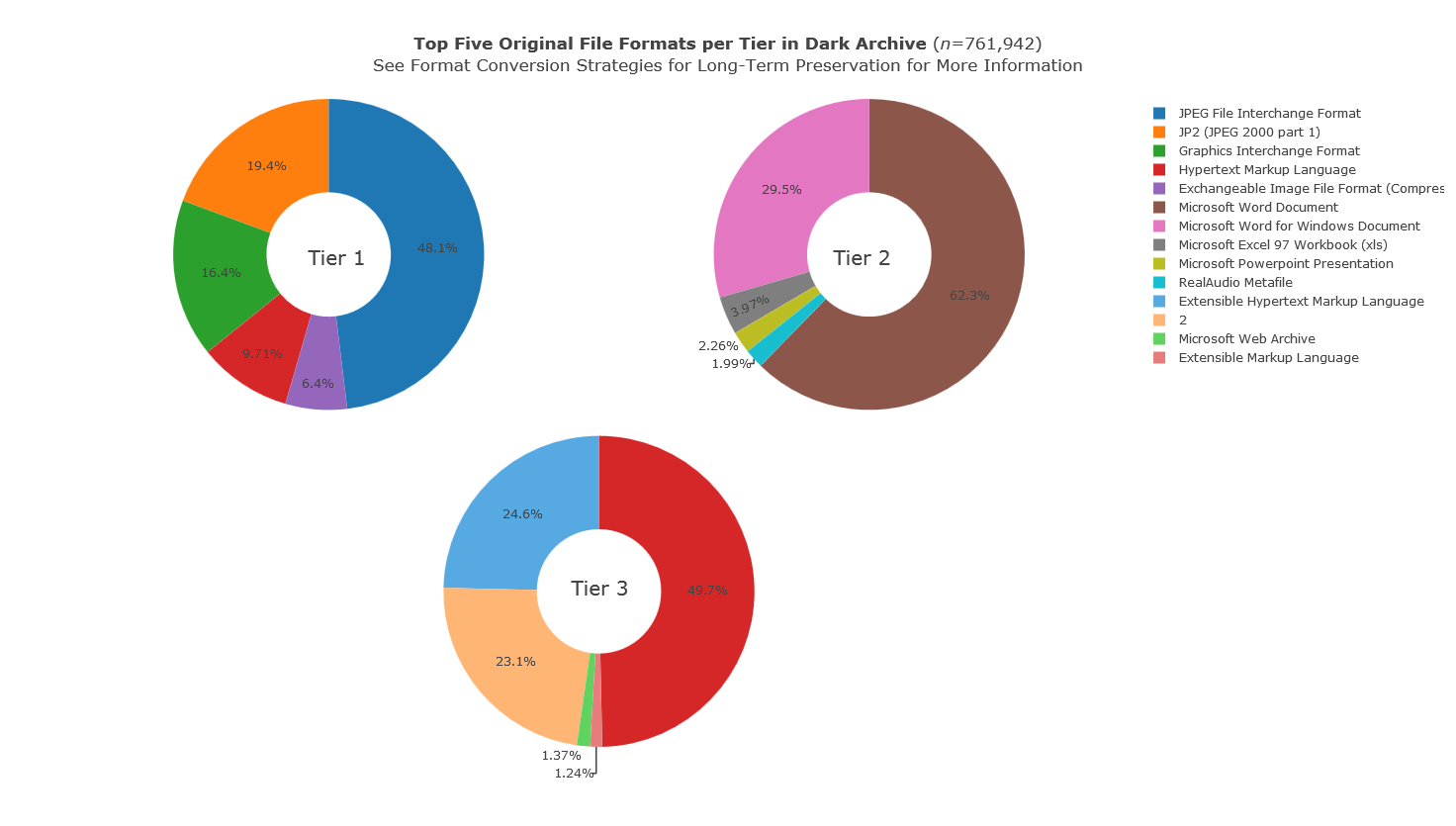
As you can see, all but one of the top five Tier 2 formats is one of those older Microsoft Office formats. What can I say? We get a lot of this kind of record!
- Formats we didn't recognize as preservation formats, and aren't an Archivematica preservation format. For these, Archivematica's normalization pathway is the same as ours.
Lots of raster images here. Examples: BMP, PCT and TGA files.
- Formats we didn't recognize as preservation formats, and aren't an Archivematica preservation format. For these, Archivematica's normalization pathway is not the same as ours.
These all stemmed from a difference in preferred preservation target for normalized video formats. We typically converted these to MP4 files with .H264 encoding, while Archivematica prefers the MKV format. Examples: SWF, FLV and WMV files.
- Formats we didn't recognize as preservation formats, and aren't an Archivematica preservation format. For these, Archivematica does not even have a normalization pathway.
Essentially, these were files that we had a normalization pathway for, but Archivematica doesn't. Examples: Real Audio files, FlashPix Bitmap and Kodak Photo CD Image files, and PostScript and Encapsulated PostScript files.
- Finally, formats we didn't recognize as preservation formats, but not even in Archivematica.
Examples: EML files and other plain text email formats.
Approaches
To be honest, I was a bit surprised by just how different our local practice was from Archivematica's, considering we both look to the same authorities on this type of thing! This diversity led to a number of different approaches to customizing Archivematica's Format Migration Strategies, which I'll briefly detail here.Do Nothing
For those formats that we agree on, i.e., we both agreed they were preservation formats or we both agreed they were not preservation formats, but shared the same normalization pathway, we didn't do anything! Easy peasy lemon squeazy.Disable a Normalization Rule, Replace a Format
This we did for formats we recognized as preservation formats, that aren't an Archivematica preservation format but that do have a normalization pathway in Archivematica. Basically, we disagreed with the out-of-the-box FPR and we weren't interested in having Archivematica doing any normalization on these. After we went to check the Library of Congress Sustainability of Digital Formats site to ensure that we weren't totally off......we went to the FPR and disabled the normalization rule...

...and verified that we'd done it correctly...

...then searched for the format itself...

...clicked "Replace"...


You can also easily verify that Archivematica got the message...

Replace a Format
A somewhat simpler approach, this we did when there were formats we recognized as preservation formats, but that aren't an Archivematica preservation format and have no normalization pathway. Since Archivematica didn't really have a better alternative, we stuck to our existing policies.This was as simple as finding the appropriate format, clicking "Replace"...

...and setting it as a Preservation format.

Create a Command, Edit a Normalization Rule
This started to get a bit more complicated. We did this for formats we didn't recognize as preservation formats, and neither did Archivematica, but Archivematica's normalization pathway is not the same as ours. Again, these all stemmed from a difference in preferred preservation target for normalized video formats.For these, Archivematica didn't have an existing command that worked for our purposes (it did have a tool, ffmpeg, that would). We had to write a little something up (which was inspired by other Archivematica commands) [2]...
...create a new normalization command...

...add in the information Archivematica needs for the new command...

...then go in and replace the rule for the appropriate format(s)...

...select the appropriate command (our new one!)...

...and finally verify that it had been changed.

Create a Normalization Rule
This we did for formats we didn't recognize as preservation formats, and neither did Archivematica, but for which Archivematica does not even have a normalization pathway (and we did). For these, we wanted to have Archivematica use our existing normalization pathway.To create a new rule, we selected the "Create New Rule" option...

...and entered the new information (purpose, original format and command you want to use) for the file format for which you're interested in created a new policy.

Manual Normalization and Other Thoughts...
That leaves us with a couple of outstanding issues, namely, legacy Microsoft Office documents and EML and other email formats (which Archivematica doesn't recognize at all--because the tools Archivematica uses for file format identification doesn't recognize them or they aren't registered in PRONOM).The "ubiquity" argument aside, we'd really love to do something about older Microsoft Office documents, especially since currently these are the most common formats that we normalize. At the moment we use LibreOffice's Document Converter to handle conversion to a more sustainable format, i.e., Microsoft Office Open XML. However, Archivematica has looked into LibreOffice with the following results:
- LibreOffice normalization led to significant losses in formatting information.
- LibreOffice sometimes hangs, causing any future LibreOffice jobs to fail until an administrator manually kills the service.
- LibreOffice sometimes reports that it succeeded despite not actually succeeding, making it difficult to determine whether or not the job really succeeded.
There may also be options here for converting to PDF as well, at least for documents. In the interim, we're still examining our options. At the very least we can change the FPR so that these formats are not recognized as preservation formats; we'll be looking into alternative approaches and will plan to report back when appropriate.
As for the email formats, we currently use a tool called aid4mail to convert these to MBOX files. This is a proprietary program, though, and only works in Windows, so we're looking into ways that we might manually normalize these files outside Archivematica (and associate different versions of files with one another inside Archivematica). This can be done, but we're looking into ways of doing this efficiently in batch, however, and again, we can plan to report back when we've got something figured out.
To the FPR and Beyond!
Alright! That's about it for customizing the FPR; I think we've covered (in at least a basic way) all the different angles (with the exception, perhaps, of introducing a new tool to Archivematica!).By the way, one of the most exciting things about the FPR is that since ours (and yours!) is actually registered with the Archivematica server, one day we all might be able to share this information in a more efficient fashion!
Have you customized the FPR? Are you too excited about the possibility of sharing FPR format policies via linked data? Let us know in the comments!
[1] Format policies are maintained by Artefactual, Inc., who provide a freely-available FPR server hosted at fpr.archivematica.org. This server stores structured information about normalization format policies for preservation and access.
[2] This could also have been written in Python.


{kind=link}
{kind=link}